Sigma2 is embarking on the procurement of its 3rd generation national storage infrastructure, the 3rd generation NIRD (National Infrastructure for Research Data). This new system will replace the current 2nd generation NIRD system and provide modern, high-performance, scalable, and secure long-term data storage, along with advanced data services for Norwegian research.
As part of this renewal, a dedicated fast-track project has been initiated to procure a tape-based storage tier, the NIRD Tape Library This library will be deployed before the other components and tiers of the 3rd gen NIRD and will be designed to integrate seamlessly with both the current 2nd generation and the next, 3rd generation NIRD. Together, these two projects will form the foundation of Sigma2’s third-generation storage infrastructure.
By definition, the new NIRD will prioritise data-centric solutions, placing data at the core of services to enhance user experience, facilitate seamless data flow, and streamline workflows for complex issues. This approach ensures that results are achieved efficiently and swiftly throughout the entire data lifecycle. NIRD will offer a comprehensive ecosystem of data services, providing optimal solutions tailored to various use cases, including AI-driven workflows, high-performance computing, and cloud services. Additionally, it will empower strong data governance and compliance alignment, ensuring the secure handling of data.
Project backgroud
NIRD has been a cornerstone of Norwegian research infrastructure since its first generation was deployed in 2017. NIRD provides storage services, advanced data services, archiving solution, secure environment, data management solution, cloud services and processing capabilities to scientific communities across all disciplines, forming the backbone of the national e-infrastructure for research and education alongside Sigma2's high performance computing resources.
Purpose of the Project
The current NIRD system is in production since 2023 and reaches end of support by 2028. This makes it necessary to initiate a new procurement now, ensuring that the 3rd-generation storage infrastructure is in place before the current system can no longer be supported and maintained.
The 3rd-generation NIRD will build upon the experience and services offered by the second-generation NIRD. It will expand the service catalog and integrate selected components into a new, more capable architecture. This will ensure the continuity of services and a smooth transition for the research community.
The 3rd-generation NIRD will also serve as the central storage solution for the next-generation Betzy super-computer. This ensures a unified namespace and smooth data flow.
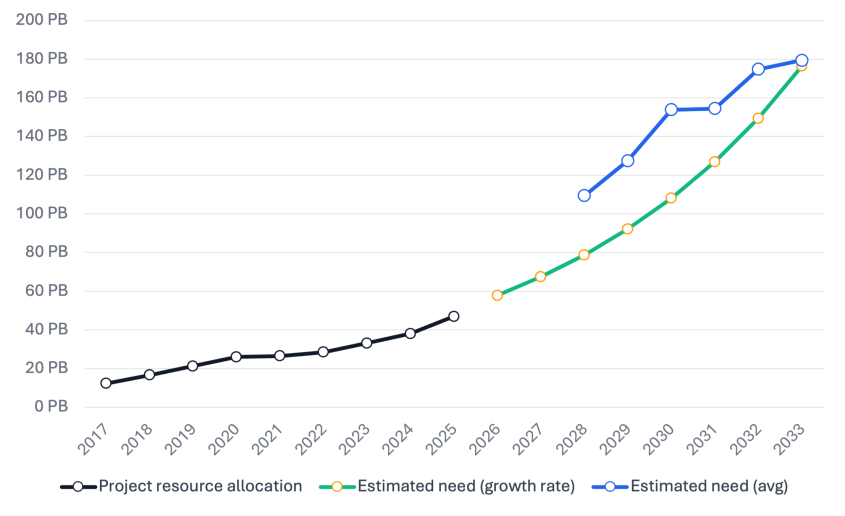
The current NIRD capacity is 75 PB and based on user survey and growth rate analysis is expected to further grow to 175-200 PB within 2032.
Procurement process
The procurement is carried out in line with the rules for public procurement.
Timeline
Market exploration
To better understand the requirements, we have prepared a set of questions which we would like to address as part of the market exploration with any possible vendor.
Generic Information
Generic Information
We are in the early stages of a procurement process and invite interested suppliers to share information about their capabilities and offerings. This is a general RFI intended to help us map the market. A more detailed RFI, including specific questions and parts of the tender documentation, will follow at a later stage. We encourage all relevant suppliers to respond.
Vendors are welcome to provide input beyond what has been specifically requested; however, any feedback should focus first and foremost on the questions listed below. Responses should be submitted as a single PDF document, structured so that each question is addressed individually and in order. Please keep responses concise and focused and avoid including bulk marketing materials or large information packages. Where relevant, vendors are welcome to reference supporting materials such as product documentation, white papers, or case studies.
Responding to this RFI does not create any obligations for the vendor and is not a prerequisite for participation in Sigma2's procurement competitions. Sigma2 is not obligated to take into account the input received. Please also note that information that cannot be classified as confidential under Section 13 of the Public Administration Act may be subject to public access under the Freedom of Information Act.
Deadline for responses: 15 September 2026
Contact point for feedback and questions: contact@sigma2.no
Data-centric Model
Sigma2 is further improving its data-centric model and the 3rd generation NIRD is intended to serve as the central storage infrastructure for research data and as the central storage platform for HPC systems, cloud platforms, and AI compute, eliminating the need for dedicated local storage on attached compute facilities.
This architecture aligns with industry best practice for disaggregated, shared storage infrastructure, where compute and storage scale independently and all workloads access a common, policy-governed data layer.
1. How would you ensure a data-centric approach? For example, data is produced on computing facility A and consumed on computing facility B, and then results from computing facility B consumed on computing facility A. Describe how your solution supports this model, including what is required on the compute side and how data is served efficiently to remote clients at scale.
2. How does your solution provide and maintain a single unified namespace across multiple systems, as described above at point 1, and across heterogeneous storage media (flash, HDD, tape) and multiple access protocols? How is namespace consistency maintained under failure scenarios?
3. How would HPC computing nodes (thousands) access the data over POSIX? How about S3?
Unified Access
4. Does your solution support simultaneous, unified access to the same data via POSIX, NFS, and S3-compatible object storage? How is consistency maintained across protocol boundaries, and what are the known limitations for each protocol interface?
5. How do you interface between file- and object storage? Do you have implementation examples?
Performance
6. What aggregate client throughput can your solution sustain, and under what configuration assumptions? Our target is 500 GB/s. Describe where bottlenecks typically occur and how your architecture addresses them. Please cite production deployments on a comparable scale.
7. What metadata operation throughput can your solution sustain? Our target is 5 million metadata operations per second. What components are responsible for metadata performance, and how do they scale as the namespace grows towards 5 billion files?
8. What is the expected network throughput for your solution? Where do you think the system has a bottleneck?
Tiering
9. Describe the storage classes/tiers your solution supports (e.g. NVMe, HDD, tape) and how data movement between them is managed.
10. Does your solution support automated information lifecycle management policies? How granularly can these policies be defined? Per file, directory, dataset, or project? Can they be managed by administrators and end users independently?
11. Does your solution support Hierarchical Storage Management (HSM) with tape as a native storage tier within the unified namespace? How are HSM operations, such as migration, and recall handled transparently for end users? What tape library systems and formats are supported?
Data Integrity
12. Does your solution support remote tape backup to an off-site location? How is this integrated? Is it policy-driven, and how is consistency between the primary namespace and the backup ensured?
13. Does your solution support snapshots at file system, dataset, and project level? Describe retention policy management, storage overhead, and whether end users can access snapshots for self-service recovery.
14. Describe your solution's failover, self-healing, and data integrity capabilities. How do you handle silent data corruption across all storage tiers, including tape? What are your RPO and RTO targets per storage class, and can resiliency policies be defined per dataset or project?
Multi-tenancy
15. How does your solution support multi-tenancy across many clients, institutions, projects, and user groups on shared infrastructure? How are access boundaries, and performance isolation enforced to prevent noisy-neighbour effects?
16. Describe the access control model your solution supports including POSIX permissions, ACLs, and any role-based, policy-based or attribute-based access control. Can controls be applied at file, object, directory, dataset, and project level by administrators? Can delegated access management be given to project owners?
Encryption
17. What encryption capabilities does your solution provide? At rest, in transit, and optionally client-side?
18. Does your solution provide key management capabilities?
19. Do you support integration with an external key management system or bring-your-own-key?
Identity and Authorisation
20. How does your solution interface with multiple identity management systems simultaneously? E.g. national federated identity providers, institutional directories, and local accounts?
21. Do you support OAuth2/OIDC alongside traditional POSIX-based authentication?
Cyber Security
22. How does your solution facilitate early threat detection, protection, and recovery?
23. Does your solution offer AI-driven security protection?
24. Is zero-trust data security implemented in the solution?
Data Management
25. Do you have data management tools in your portfolio? Can this be used with solutions from other vendors?
26. Describe your metadata management capabilities, including support for structured metadata schemas, metadata search, and integration with data catalogues. Does your solution support data cataloging?
27. Does your solution support semantic search? Can data be found based on data content, metadata or detected attributes? How would your solution support RAG pipelines?
Monitoring and Reporting
28. Do you provide monitoring and usage reporting at dataset and project level? Does your solution support chargeback or back-charging models?
29. What observability interfaces do you expose (e.g., metrics endpoints, log streams) for integration into an operator's existing monitoring stack?
Service continuity
30. NIRD must preserve continuity of existing services covering active high-performance storage, a data lake, a curated central data library, and a long-term research data archive, portals, etc. What migration tooling and coexistence capabilities do you provide? How would you approach a phased transition from an existing platform?
Operations
31. What are the prerequisites for deploying your solution into an existing HPC environment (OS, kernel, network fabric)? Do you support rolling upgrades with no service interruption? Describe the expected level of ongoing operator interaction, automated vs. manual, for routine operations and failure recovery.
Cost Structure
32. What are the primary cost drivers in your solution at scale: hardware, software licensing, support, or other factors? Describe your licensing model and how pricing scales with capacity, file count, usage, and number of concurrent users or protocols.
33. How do you engage with open standards to limit vendor lock-in?
References
34. Provide reference customers operating at comparable scale and complexity.
Data Centric Model
The Data Centric Model is Sigma2's strategic response to the convergence of HPC, cloud, and AI workloads and leads with the Sigma2’s strategic vision of user in focus.
Rather than attaching dedicated storage to each compute facility, NIRD (Norwegian Infrastructure for Research Data) becomes the shared, persistent data plane for all compute systems.